
Posts By jhaluska
Retro Game Development
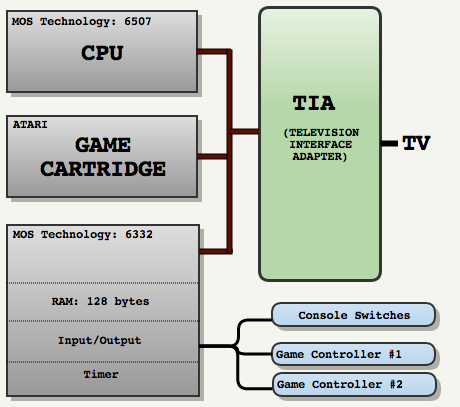
I have an interest in understanding the game software and hardware of yesteryears. I came upon Fabien Sanglard’s website who goes into technical details about games and hardware with a lot of wonderful visual diagrams. I deeply appreciate people like him who have both the knowledge, talent and patience to write it up for people like me.
Valve using Deep Learning to Bust Cheaters
Remember my earlier post about using Fitt’s law to bust Aim Bots? Well Valve basically automated that using Deep Learning. We’re going to see a lot of human tasks associated with classification being replaced with deep learning.
Inverse Square Hack
I just wanted to pay homage to one of the most brilliant programming optimizations. This Inverse Square write up should be required reading to show how much thought can go into a single line of code. In my life I probably will never write a line of code that is as beautiful in it’s intimate knowledge of math and low level computer expertise.
Adventures in Installing PyTorch in Ubuntu 18.04
I wanted to document installing PyTorch on Ubuntu 18.04 just in case it could be useful to myself or others in the future. I tried to combine videos and forum posts together on this topic.
1. In Software & Updates, on the Ubuntu Software tab, check the “Proprietary drivers for devices” and “Software restricted by copyright or legal issues”.
2. On the Additional Drivers tab, change the driver to "Using NVIDIA driver metapackage nvidia-driver-390 (proprietary, tested)"
 2. Reboot to load drivers.
3. Check to make sure the driver was installed correctly with:
$ nvidia-smi
2. Reboot to load drivers.
3. Check to make sure the driver was installed correctly with:
$ nvidia-smi

3. Install the NVidia Cuda Toolkit $ sudo apt update $ sudo apt install nvidia-cuda-toolkit
4. Check to make sure it is installed correclty with: $ nvcc –version
5. Download Anaconda which is used to install PyTorch. The latest version can be found on the official site. $ wget https://repo.anaconda.com/archive/Anaconda3-5.1.0-Linux-x86_64.sh
6. Make the script executable and run it. $ chmod u+x Anaconda3-5.1.0-Linux-x86_64.sh $ ./Anaconda3-5.1.0-Linux-x86_64.sh
7. Check to make sure it is installed with: $ python --version $ conda --version
5. Use Anaconda to install PyTorch: $ conda install pytorch torchvision cuda91 -c pytorch
6. Test it with: $ ipython
import torch t = torch.rand(5) r = t.cuda() r

The Early Days of Branch Prediction
Read this quick article on CPU branch prediction. I feel like a decent understanding of CPU hardware design, but in reality I only know the low level details till about 92. Since older CPUs are simpler, they are easier to understand and were developed but much smaller teams. Modern CPUs are designed by massive teams and each are specializing in certain areas. It’s interesting to see how topics like branch prediction evolve to use more transistors to get better results.
Building an OCR Pipeline with Tesseract
I’m going to give some details to some future software engineers on how to get the most out of Tesseract OCR. My company, Zorbu, is currently doing some small business software automation. Last year, I needed to process faxes for automatic data entry. Before looking at commercial systems I always investigate open source. I’m going to tell you what was first used in production.
First off, Tesseract is very temperamental software. It took me about a month of work to get it processing well enough for production. The key to improving results is taking over tasks that Tesseract says it does with superior modern versions.
1. Remove Vertical Lines (Optional)
If you’re processing faxes, you might be amazed to find out how often they have vertical black lines through them. The lines are caused from dirty or damaged sensors. These lines wreck havok on Tesseract’s recognition. Tesseract does better with gaps in text than extra lines. Figure out a way to filter out the black lines and you’ll see your results improve. This is easiest and fastest to do first.
2. Double the Scale
This seems like it would add no new information, but this by far the biggest improvement especially with small fonts, and low resolutions. Even if you can read it perfectly, tesseract will struggle with it. I found bilinear works, but bicubic may improve results further. There are two ways that I believe this helps. There are are some fixed sizes in Tesseract that makes the character matching less accurate as it’s not granular enough. Second, most modern faxes are color and Tesseract processes strictly black/white images. By doubling the size you are better able represent the actual shape of the characters when it’s turned into black and white.
3. Deskew the Document
Another task that Tesseract claims to handle is document deskewing. I found modern techniques do a better job, at least my accuracy went up. It also makes it easier to do more processing.
4. Convert to Black and White.
This needs to be done after deskewing and resizing. The goal in handling it yourself is producing a very consistent character size and thickness. You may need to do some image analysis to get the results you want. This needs to be done after deskewing and resizing or you lose too much information.
5. Train Tesseract on the Font
This was very tedious and frustrating experience. Tesseract is not modern and most of the errors are cryptic and confusing. I wrongfully thought that giving Tesseract more examples was the way to go…nope my results went down. I found it’s best to train on single ideal examples. Except you might not have that. Even knowing the font, I found out it wasn’t the same due to the resolution differences. I ended up making super resolution versions of the characters, converting it to black and white and showing a single example of each character.
6. Process Twice
I would first use Tesseract with the default english settings to get the text to classify. I would then run it again with my custom language/font.
7. Use White Lists
This part is somewhat obvious, but you can set the “tessedit_char_whiltelist” variable to just the characters that show up in the document.
8. Reprocess characters/word/letters with smaller white lists
Even with all this work, I had a lot of trouble with Os and 0s with Tesseract. The more you restrict Tesseract, the more likely it will get the correct results. If you know there is only a single character, let it know that via the page segementation mode. If you know it’s a single word, let it know. If it’s just a number restrict it. I went so far as to restrict the tens’s place of a month to 0-3.
Tesseract is fickle software, but with some preprocessing you can get improved results.
The Game Boy, Memory Mapping
I think older technology shouldn’t be discounted. They’re excellent educators with many principals being applied to modern development. Learn about memory mapping, some assembly, gaming and more in this excellent video.
Inside the Game Boy Part 1: The CPU
Every once in a while I come across an article that I wish I had when I was learning programming. This one is a fast introduction to the Game Boy. It even includes some ASM that covers an iconic platform.
Could Fitts’s Law be used to detect Aim Bots?
I have been thinking about how we decide if a person is cheating in some online games. More than once my gaming experience has been ruined by a sniper who suddenly seems to hit my head out of nowhere. In some games, you can spectate through their view. Sometimes it’s obvious snapping and tracking that is inhumane. Other times it’s more subtle when a person can trigger the aim bot only in certain times. But how could we automate detection of at least the most glaring cheaters?
While we often think of the games as defying physics, they actual inputs are tied to people who are confined to the physical world. The mouse is moved by a human hand which can’t accelerate instantly nor stop instantly. If we assume this is to be the case, we could use Fitt’s Law as a way to determine if their movements confine to real world physics. This would need to be done by the game manufacturer behind the scenes, as the actual data isn’t provided to the end user.
In each first person shooter game there are hit boxes that a person wants to hit, usually the head or the body. This could be considered the target. These are often determined by height and width, which are inputs into Fitt’s Law. Smaller targets that further away are thus harder to hit, and often take more time to aim. Through observing a known human play you could determine what is possible within human parameters that confine to Fitt’s Law. This would mean, rapid re-aiming to small spots could be quantifiable determined the likelihood that the person is cheating.
The hard part isn’t using Fitt’s Law, it is determining from the mouse movements when a person makes a judgement to move their mouse to what target. Also sometimes people just get lucky and hit somebody they weren’t even thinking to hit. But I think through repeated observations and some analysis, aim botting would get less feasible, because at best you could have it turn you into the best human player, not the best machine player.
I used to think CPUs required massive amounts of transistors beyond most human’s comprehension. But the Nibbler 4 Bit CPU shows that the basics don’t require as many chips as you would think.
Recent Comments